6.2 Explorando los datos por clase social
Al estudiar las desigualdades desde una perspectiva de clases, una primera aproximación al problema puede comenzar explorando el modo en que los distintos indicadores, que consideramos como variables dependientes, se distribuyen entre las distintas posiciones. En este sentido, las medidas de tendencia central, así como las de dispersión, pueden ser buenas herramientas en esta etapa.
Tomando como variable dependiente los ingresos totales individuales (P47T), calcularemos el promedio por clase social. Para ello utilizaremos algunas funciones del paquete dplyr y de R base como weighted.mean. Tomaremos como punto de partida, los datos que hemos trabajado en los capítulos anteriores de la EPH del segundo trimestre de 2015.
eph_ind_215 %>%
filter(!is.na(clase6_factor)) %>%
group_by(clase6_factor) %>%
summarise(media = weighted.mean(P47T, w = PONDERA))# A tibble: 6 × 2
clase6_factor media
<fct> <dbl>
1 Clase alta 15723.
2 Clase media - autónoma 8527.
3 Clase media - asalariada 9738.
4 Clase obrera - autónoma 5509.
5 Clase obrera - asalariada 7151.
6 Clase obrera - trabajadores marginales 3792.Como puede observarse, las posiciones de clase son explicativas de la desigualdad de ingresos. A mayor posición de clase, mayores ingresos percibidos. A su vez, existen fronteras, en términos de ingresos, entre la clase media y obrera, así como entre los estratos autónomos y asalariados. Sin embargo, la media es una medida que no da una caracterización completa respecto a la distribución de los valores. Para ello comúnmente se utilizan las medidas de posición y de dispersión como forma de conocer cuán homogéneas o heterogéneas son las distribuciones de los datos, en este caso, de los ingresos. El diagramas de caja (o en inglés boxplot), nos permite a partir de una salida gráfica, dar cuenta de una serie de estas medidas. Con ayuda del paquete ggplot2 y la función geom_boxplot presentamos el siguiente gráfico. Para facilitar la visualización, seleccionamos únicamente los casos con ingresos hasta $40.000.
eph_ind_215 %>%
filter(!is.na(clase6_factor), P47T <= 40000) %>%
ggplot(aes(x = clase6_factor, y = P47T, fill = clase6_factor, weight = PONDERA)) +
geom_boxplot(outlier.alpha = 0.1, show.legend = FALSE) + labs(y = "Ingresos totales individuales",
caption = "Elaboración propia en base a EPH-INDEC 2015") + theme(plot.caption = element_text(size = 9),
axis.title.x = element_blank(), axis.title.y = element_text(size = 10), axis.text.x = element_text(size = 10),
axis.text.y = element_text(size = 10)) + scale_x_discrete(labels = function(x) str_wrap(x,
width = 20)) + scale_y_continuous(breaks = seq(0, 50000, 5000))Gráfico 6.2: Ingresos totales individuales por clase social
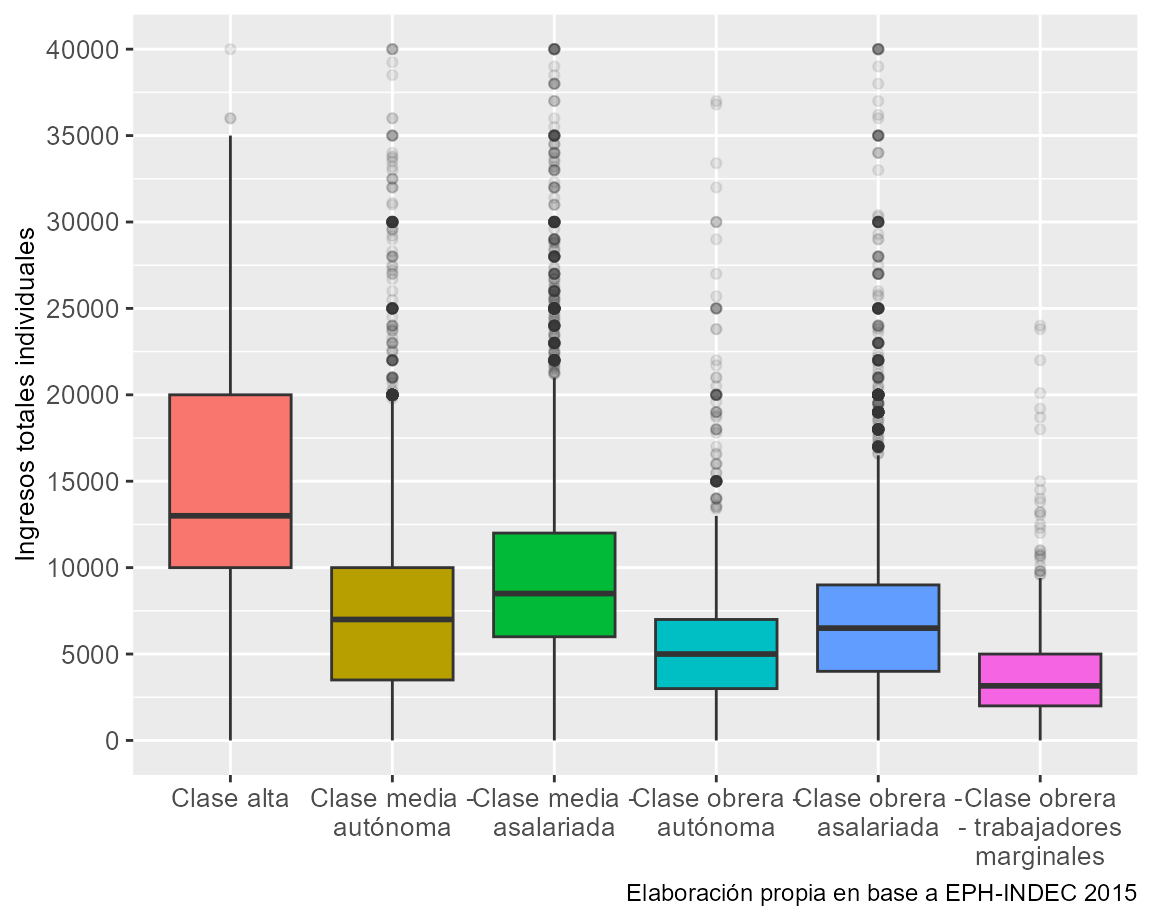
Varios son los elementos del gráfico que debemos destacar. En primer lugar, las cajas dan cuenta del rango inter-cuartil (1ro y 3ro), mientras que las lineas representan a las medianas de ingresos, es decir, el valor que parte a la distribución por la mitad. De esta forma, los resultados se muestran similares a los arribados en la tabla anterior, aunque las clases medias y la clase alta muestran cierta heterogeneidad en los ingresos percibidos. Finalmente, los límites de las lineas verticales representan los valores máximos y mínimos, mientras que los puntos identifican a los casos atípicos.